Doris Docker#
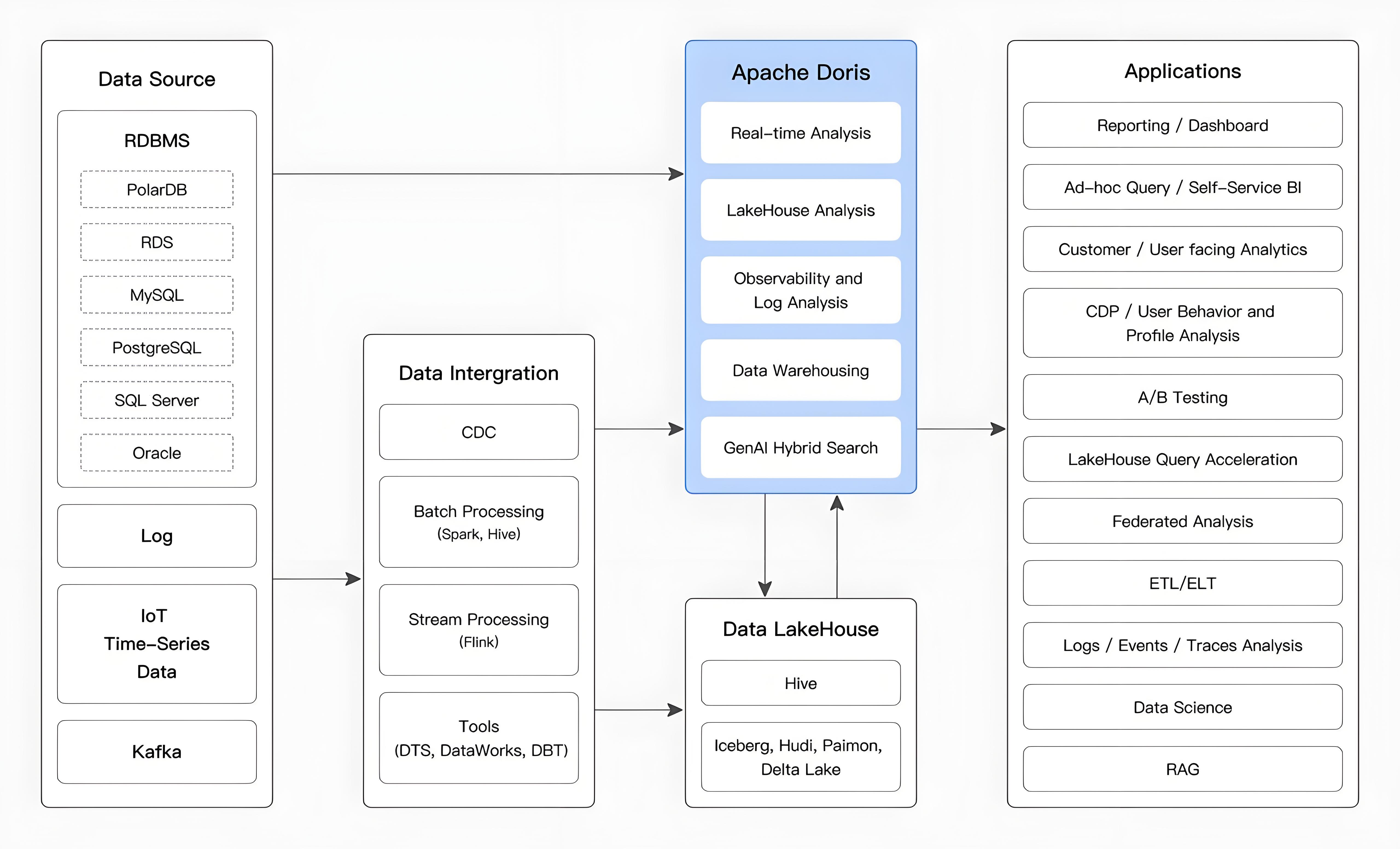
Apache Doris 是一款基于 MPP 架构的高性能、实时分析型数据库。它以高效、简单和统一的特性著称,能够在亚秒级的时间内返回海量数据的查询结果。Doris 既能支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。
基于这些优势,Apache Doris 非常适合用于报表分析、即席查询、统一数仓构建、数据湖联邦查询加速等场景。用户可以基于 Doris 构建大屏看板、用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析等应用。
快速体验 Apache Doris#
警告:以下快速部署方法仅用于本地开发和测试,请勿用于生产环境。原因如下:
数据易丢失: Docker 部署在容器销毁时会丢失数据;手动部署单副本实例不具备数据冗余备份能力,机器宕机可能导致数据丢失。
单副本配置: 示例中的建表语句均为单副本,生产环境应使用多副本存储数据,以保证数据可靠性。
Doris 2.1#
doris.ymlUser: root | admin / 密码为空
Tips#
doris-be | Please set vm.max_map_count to be 2000000 under root using ‘sysctl -w vm.max_map_count=2000000’. 解决办法:
# 在宿主机(物理机/虚拟机)执行
sudo sysctl -w vm.max_map_count=2000000
doris-be | Please disable swap memory before installation. 解决办法:
# 在宿主机(物理机/虚拟机)执行
sudo swapoff -a
数据库连接#
Apache Doris 采用 MySQL 网络连接协议,兼容 MySQL 生态的命令行工具、JDBC/ODBC 和各种可视化工具。
MySQL Client#
# FE_IP 为 FE 的监听地址,FE_QUERY_PORT 为 FE 的 MYSQL 协议服务的端口,在 fe.conf 中对应 query_port, 默认为 9030.
mysql -h FE_IP -P FE_QUERY_PORT -u USER_NAME
mysql -h 127.0.0.1 -P 9030 -uroot
Tests#
-- 创建数据库
CREATE DATABASE test_db;
-- 使用数据库
USE test_db;
-- 创建表
CREATE TABLE user_pv (
user_id INT,
username VARCHAR(32),
pv BIGINT SUM
)
AGGREGATE KEY(user_id, username)
DISTRIBUTED BY HASH(user_id) BUCKETS 8
PROPERTIES("replication_num" = "1");
-- 插入数据
INSERT INTO user_pv VALUES (1, '张三', 100);
INSERT INTO user_pv VALUES (2, '李四', 150);
-- 查询数据
SELECT username, SUM(pv) AS total_pv
FROM user_pv
GROUP BY username
ORDER BY total_pv DESC;
Runtime Environment#
C++
使用场景#
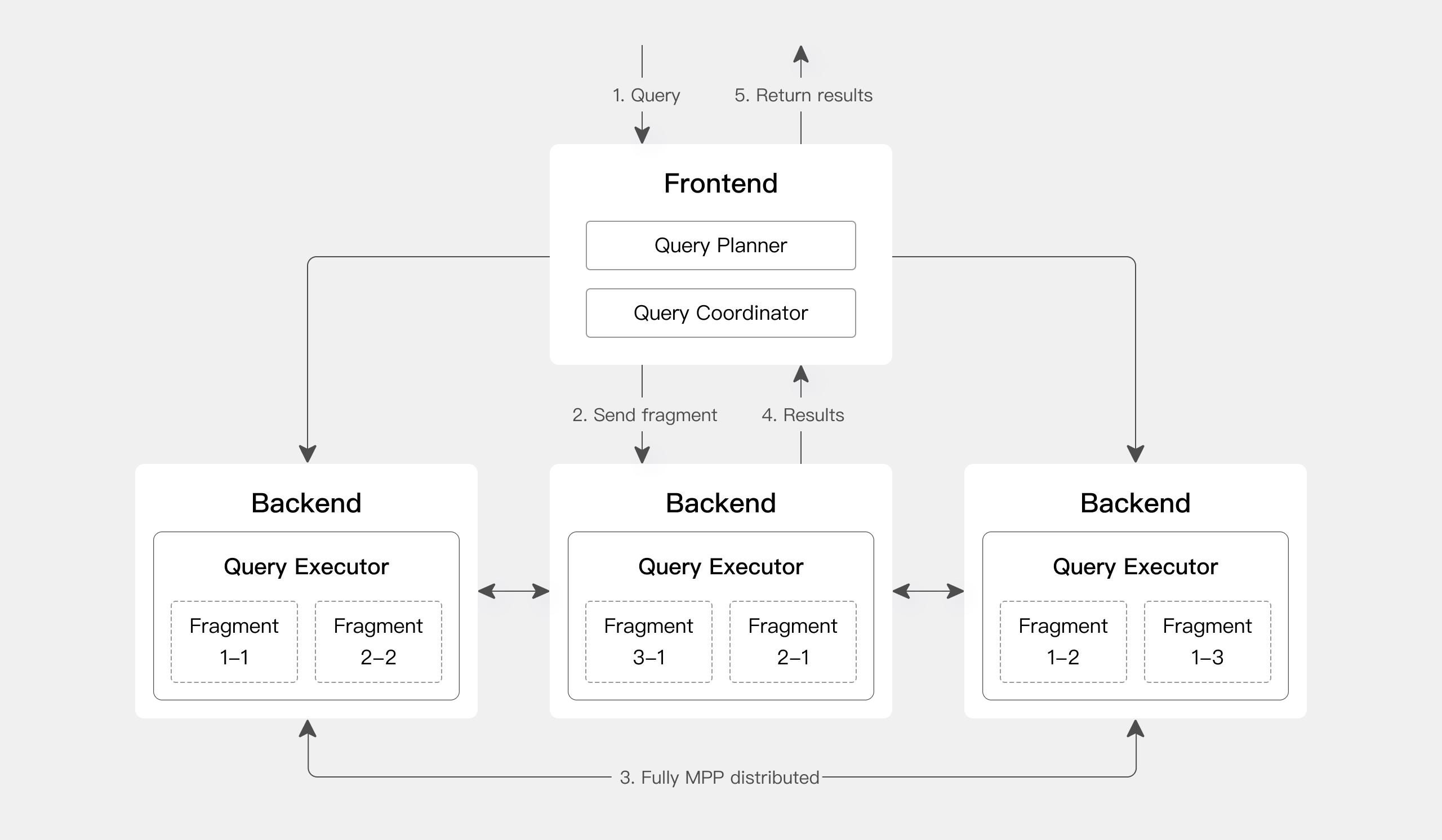
Architecture#
Frontend (FE): 主要负责接收用户请求、查询解析和规划、元数据管理以及节点管理。
Backend (BE): 主要负责数据存储和查询计划的执行。数据会被切分成数据分片(Shard),在 BE 中以多副本方式存储。
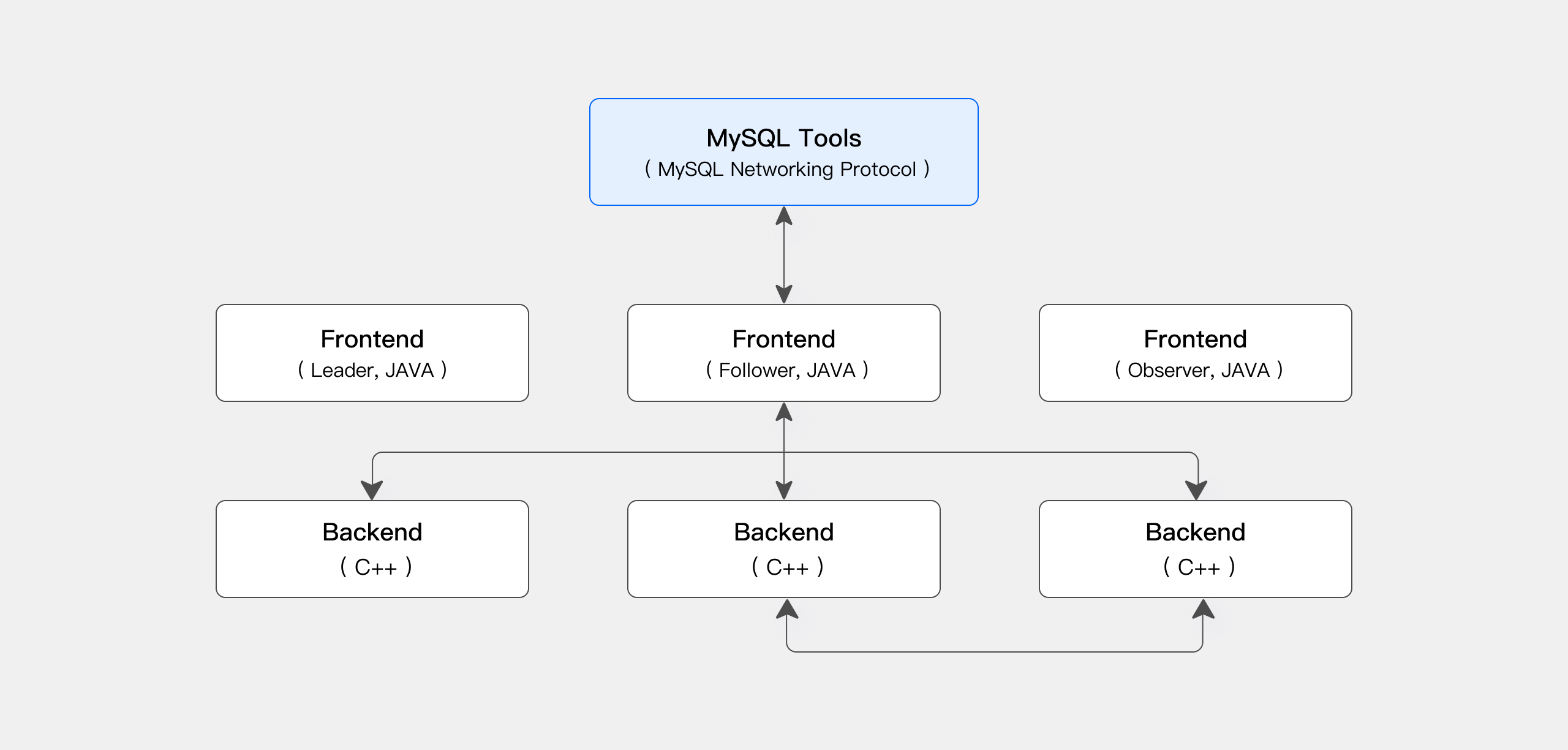
| 角色 | 功能 |
|---|---|
| Master | FE Master 节点负责元数据的读写。当 Master 节点的元数据发生变更后,会通过 BDB JE 协议同步给 Follower 或 Observer 节点。 |
| Follower | Follower 节点负责读取元数据。当 Master 节点发生故障时,可以选取一个 Follower 节点作为新的 Master 节点。 |
| Observer | Observer 节点负责读取元数据,主要目的是增加集群的查询并发能力。Observer 节点不参与集群的选主过程。 |
查询引擎#
Apache Doris 采用大规模并行处理(MPP)架构,支持节点间和节点内并行执行,以及多个大型表的分布式 Shuffle Join,从而更好地应对复杂查询。