LocalAI Docker#
LocalAI is the free, Open Source OpenAI alternative. LocalAI act as a drop-in replacement REST API that’s compatible with OpenAI API specifications for local inferencing. It allows you to run LLMs, generate images, audio (and not only) locally or on-prem with consumer grade hardware, supporting multiple model families and architectures.
Docker#
docker run -p 8080:8080 --name local-ai -ti localai/localai:latest-aio-cpu
# Do you have a Nvidia GPUs? Use this instead
# CUDA 11
# docker run -p 8080:8080 --gpus all --name local-ai -ti localai/localai:latest-aio-gpu-nvidia-cuda-11
# CUDA 12
# docker run -p 8080:8080 --gpus all --name local-ai -ti localai/localai:latest-aio-gpu-nvidia-cuda-12
Docker Compose#
version: "3.9"
services:
api:
image: localai/localai:latest-aio-cpu
# For a specific version:
# image: localai/localai:v2.17.1-aio-cpu
# For Nvidia GPUs decomment one of the following (cuda11 or cuda12):
# image: localai/localai:v2.17.1-aio-gpu-nvidia-cuda-11
# image: localai/localai:v2.17.1-aio-gpu-nvidia-cuda-12
# image: localai/localai:latest-aio-gpu-nvidia-cuda-11
# image: localai/localai:latest-aio-gpu-nvidia-cuda-12
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/readyz"]
interval: 1m
timeout: 20m
retries: 5
ports:
- 8080:8080
environment:
- DEBUG=true
# ...
volumes:
- ./models:/build/models:cached
# decomment the following piece if running with Nvidia GPUs
# deploy:
# resources:
# reservations:
# devices:
# - driver: nvidia
# count: 1
# capabilities: [gpu]
Run models manually#
mkdir models
# Download luna-ai-llama2 to models/
#wget https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GGUF/resolve/main/luna-ai-llama2-uncensored.Q4_0.gguf -O models/luna-ai-llama2
wget https://hf-mirror.com/TheBloke/Luna-AI-Llama2-Uncensored-GGUF/blob/main/luna-ai-llama2-uncensored.Q4_0.gguf -O models/luna-ai-llama2
# Use a template from the examples, if needed
cp -rf prompt-templates/getting_started.tmpl models/luna-ai-llama2.tmpl
#docker run -p 8080:8080 -v $PWD/models:/models -ti --rm quay.io/go-skynet/local-ai:latest --models-path /models --context-size 700 --threads 4
docker run -p 8080:8080 -v $PWD/models:/models -ti --rm quay.io/go-skynet/local-ai:latest-aio-cpu --models-path /models --context-size 700 --threads 4
# Now the API is accessible at localhost:8080
curl http://localhost:8080/v1/models
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "luna-ai-llama2",
"messages": [{"role": "user", "content": "How are you?"}],
"temperature": 0.9
}'
Try it out#
Text Generation#
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{ "model": "luna-ai-llama2", "messages": [{"role": "user", "content": "How are you doing?", "temperature": 0.1}] }'
Runtime Environment#
Architecture#
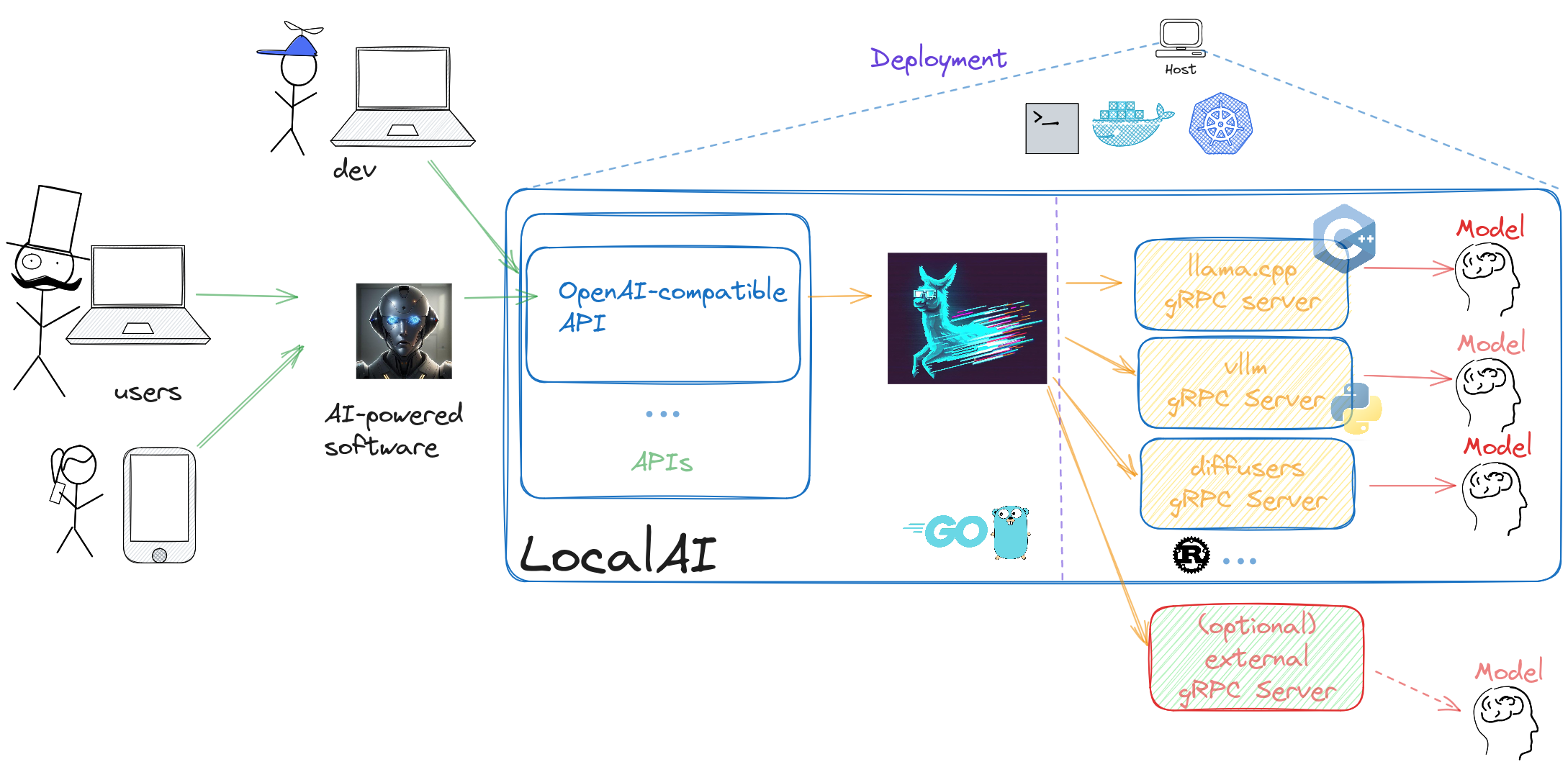
Screenshots#